Can AI predict whether or not you get a job after you graduate?
12/15/2025
I rarely go out of my way to read the news. Every single time I decide to search up “news” in Google, there’s always something that seems to be going horribly wrong. It almost seems like every article is screaming at me, telling me I’m doomed, for whatever reason. Whether it’s hikes in the cost of living, new influenza with record-breaking hospitalizations, the stock market crashing, or corrupt politicians, there is always something to be worried about.
So I just simply avoid reading the news.
And this shields me quite well. But sometimes, inevitably, a piece of news will always trickle through to me. In recent days, the state of the job market, particularly for new graduates, has been revealed to me.
Getting a job as a new graduate, in almost any field right now, looks absolutely dire—and that’s putting it lightly. I read today in an article that, according to “Indeed,” the number of roles advertised for recent graduates was 33% lower than a year ago! That is absolutely insane.
It’s hard to say what the reason for this is, but many people attribute it to the rise in AI. I’m personally not so sure about that. I’d argue the state of the economy and the fact that we are essentially in a recession has more of a part to play—then again, I don’t really have any expertise regarding this. But this did make me wonder: could “AI” be used in some way to help new graduates out instead? (I put “AI” in quotes because what I’m going to discuss here is specifically machine learning.)
I’m not sure how much this would help, but what if we could make a machine learning model (if you don’t know what that is, just pretend it’s a mobile app) that could predict whether or not a certain new graduate could get a job?
Machine Learning Models
If you are not in the tech space, you probably have no clue what a machine learning model is. And, honestly, there is no reason for you to know what it is.
But not knowing what it is doesn’t matter, because you’ve most definitely used one in your life. For example, the system your email inbox has in place that puts suspicious emails in a spam folder. That is a type of machine learning model called a “classifier,” which is precisely what we will use to predict whether a student can land a job or not.
Classification Model:
The idea behind a classification model is simple:
It simply uses data about a thing to classify that thing into a certain group.
Not making any sense? How about an example:
Think back to the system I just mentioned in your email inbox that places suspicious mail in your spam folder. It’s able to do this because when you get a new email, it looks at different things about it, like the word count, certain words it’s used, the sender’s email, and the subject. The model then compares each of these to examples of “spam” emails and will either classify it as not spam or spam—that's all there is to it.
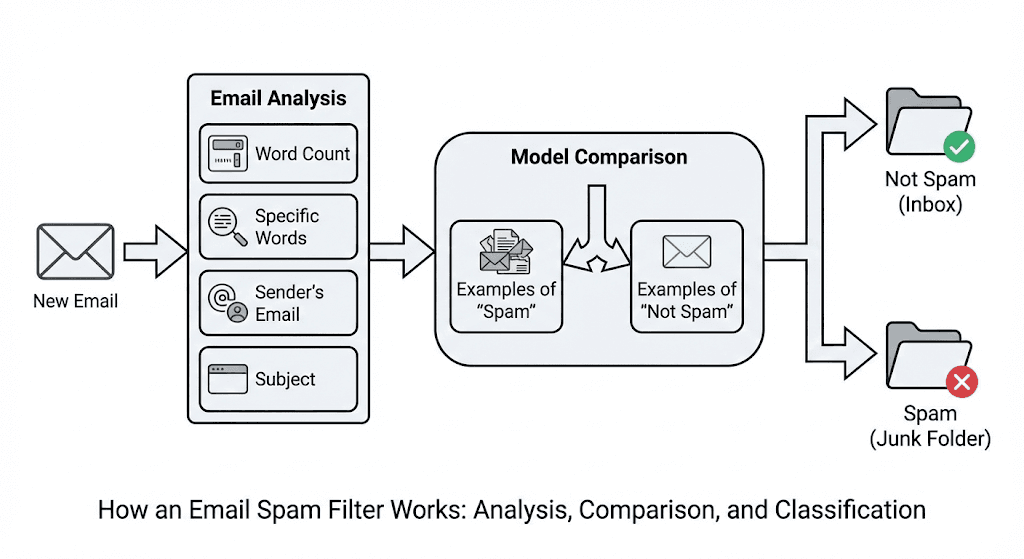
In our case, we want a system that will look at details about a student, i.e. the university attended, grade achieved, and subject studied, and compare students with similar backgrounds to predict or classify whether a student will get a job or not after graduating.
Building a model:
So how do we do this?
I only aim to give the intuition behind making a prediction. I don’t want to go into details about machine learning concepts and maths. So we will start off very simple.
Think of two things that might affect whether a student will get a job.
Done?
There are probably hundreds of factors that would affect whether a student will get a job. For this blog, we will go with the ranking of the university they attended and the grade they achieved. Chances are, if they go to a high-ranking university and achieve a high grade, it’s likely they will get a job after graduating—at least you would hope so…
Lets make a graph out of this:
Okay, now let’s look at data from the past and put it on the chart. So, for example, let’s say there was a student from 2021 who went to the first-ranked university and achieved 75%; we’d put a dot at (1, 75) on the chart. We will also mark the dots to identify the students that got a job and those who didn’t. If they didn’t get a job, we mark them with a brown dot; if they did, we mark them with a purple dot.
This is what it looks like:
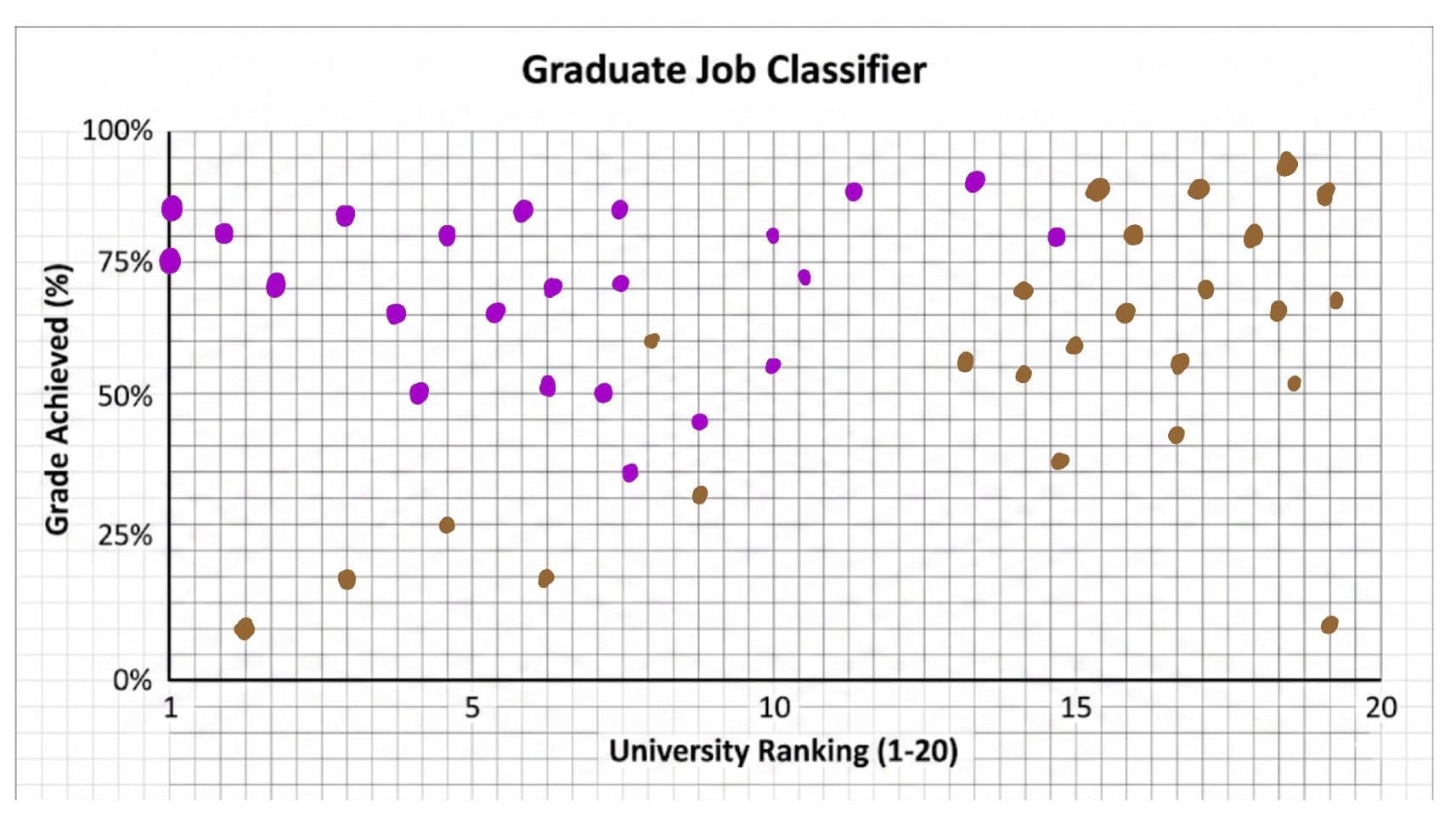
Just a disclaimer: this is all fake data, of course. In reality, it would probably look nothing like this, but we are just using it as an example.
From the graph, just by looking, we can see that going to a highly ranked university definitely helps your chances of getting a job. But how do we use this to make predictions?
We need to make a line that separates the purple dots from the brown dots, such that MOST of the dots above the line are purple and MOST of the dots below the line are brown. I say most, because it would be impossible to make a perfect line that separates both.
Here’s what I’ve got:
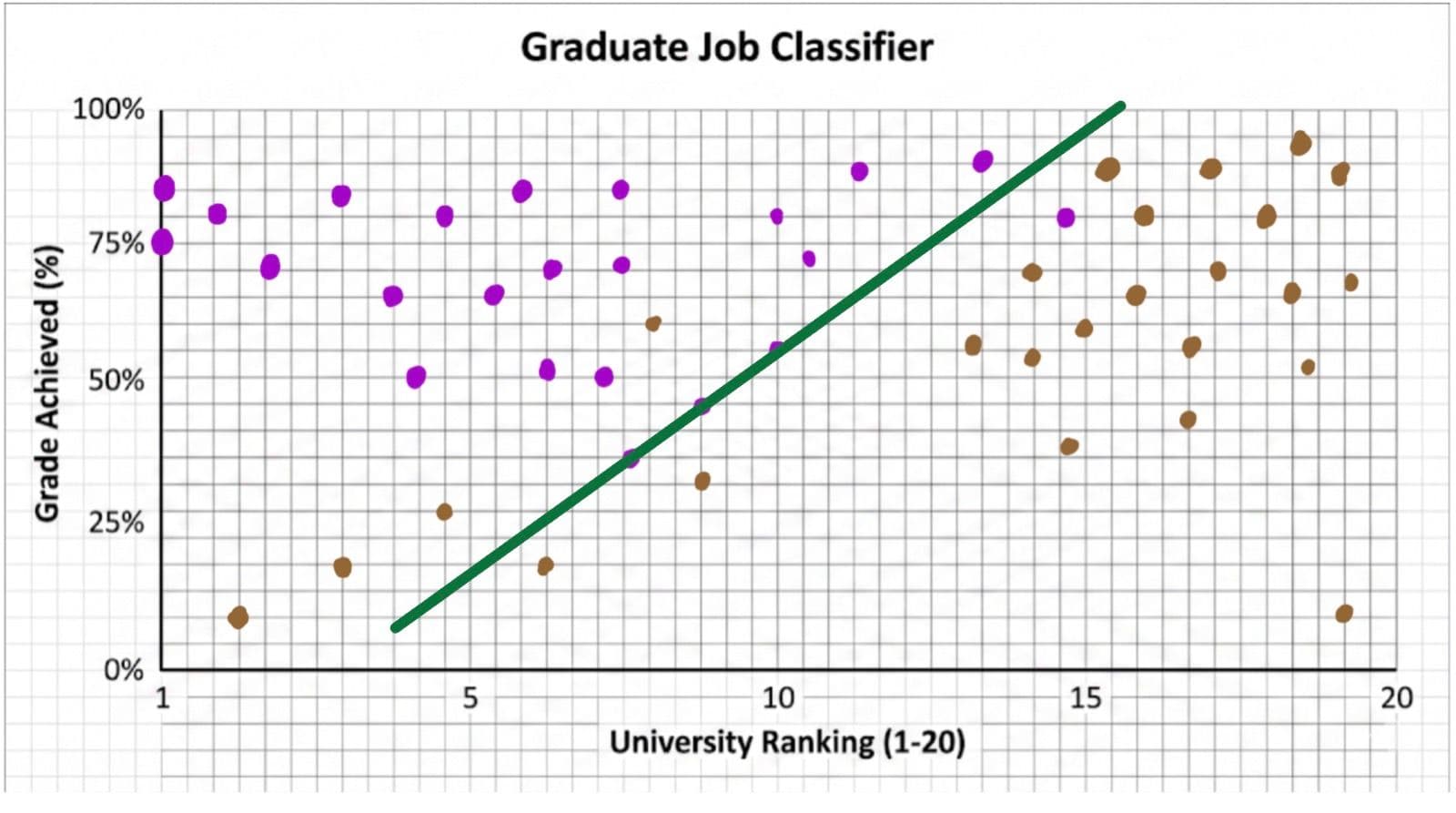
So now, if I want to predict whether a student gets a job after university, I would simply look at their university ranking and the grade they are predicted to achieve and mark a dot there. If they are below the line, then I would predict they wouldn’t get a job; if they are above the line, then I predict they would get a job.
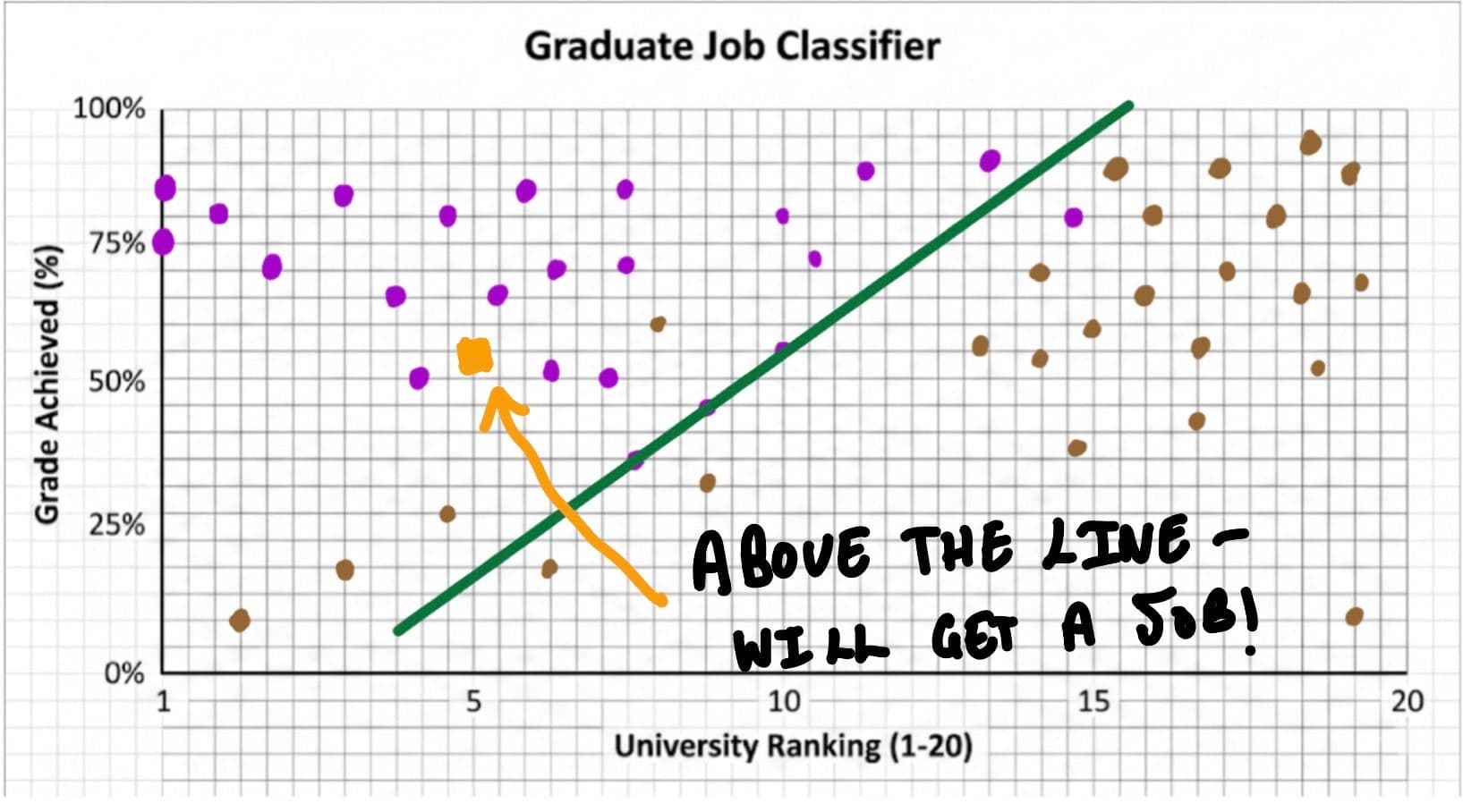
BOOM! We’ve just made a classification model.
Going Further:
In reality, this is a garbage model. There are WAY more things that would determine whether or not a student will get a job, such as the state of the economy, the number of open positions, and the field they graduate in. But to explain how we would build a classification model based on all this would be quite advanced. If you are interested in knowing how to make better predictions with more factors, I’d suggest researching “Classification Models in Machine Learning” on the internet. There are tons of amazing resources out there, and you have the intuition of what we’re trying to achieve now.